
Fasttext是Facebook AI Research最近推出的文本分类和词训练工具,其源码已经托管在Github上。Fasttext最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快,在普通的CPU上可以实现分钟级别的训练,比深度模型的训练要快几个数量级。同时,在多个标准的测试数据集上,Fasttext在文本分类的准确率上,和现有的一些深度学习的方法效果相当或接近。
最近一直在做微信广告文章分类的工作,正好顺手研究了下Fasttext,并在微信广告文章识别上做了一些尝试。因为代码开源的时间不长,网上相应的文章和资料还比较少, 希望这篇文章对想了解和使用Fasttext做文本分类的同学有所帮助。
原理
介绍原理之前,我们先稍微聊一点八卦。Fasttext的其中一个作者是Thomas Mikolov。熟悉word2vec的同学应该对这个名字很熟悉,正是他当年在Google带了一个团队倒腾出来了word2vec,很好的解决了传统词袋表示的缺点,极大地推动了NLP领域的发展。后来这哥们跳槽去了Facebook,才有了现在的Fasttext。从“血缘”角度来看,Fasttext和word2vec可以说是一脉相承。
回到正题,Fasttext主要有两个功能,一个是训练词向量,另一个是文本分类。词向量的训练,相对于word2vec来说,增加了subwords特性。subwords其实就是一个词的character-level的n-gram。比如单词”hello”,长度至少为3的char-level的ngram有”hel”,”ell”,”llo”,”hell”,”ello”以及本身”hello”。每个ngram都可以用一个dense的向量$z_g$表示,于是整个单词”hello”就可以表示表示为:
具体细节可以参考论文Enriching Word Vectors with Subword Information,这里就不展开叙述了。那么把每个word,拆成若干个char-level的ngram表示有什么好处呢?其实细想一下也非常容易理解,无非就是丰富了词表示的层次。比方说”english-born”和”china-born”,从单词层面上看,是两个不同的单词,但是如果用char-level的ngram来表示,都有相同的后缀”born”。因此这种表示方法可以学习到当两个词有相同的词缀时,其语义也具有一定的相似性。这种方法对英语等西语来说可能是奏效的,因为英语中很多相同前缀和后缀的单词,语义上确实有所相近。但对于中文来说,这种方法可能会有些问题。比如说,”原来”和”原则”,虽有相同前缀,但意义相去甚远。可能对中文来说,按照偏旁部首等字形的方式拆解可能会更有意义一些。
Fasttext的另一个功能是做文本分类。主要的原理在论文Bag of Tricks for Efficient Text Classification中有所阐述。其模型结构简单来说,就是一层word embedding的隐层+输出层。结构如下图所示:
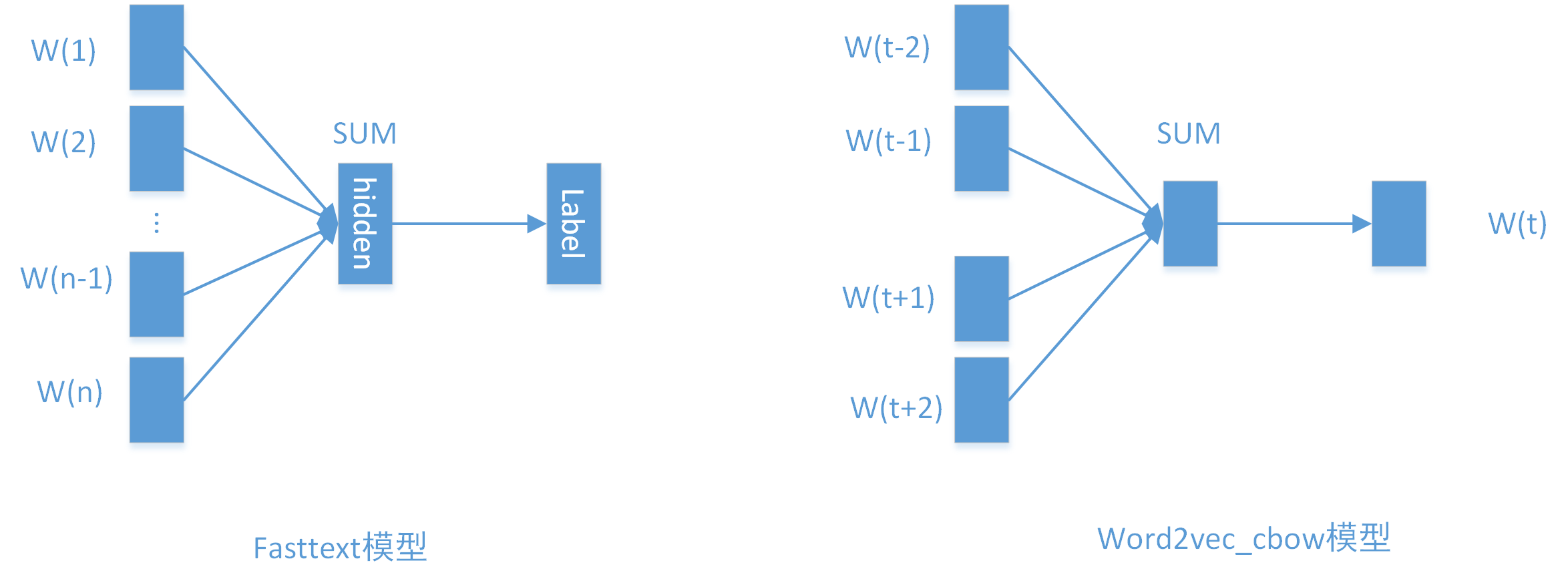
上图中左边的图就是Fasttext的网络结构,其中W(1)到W(n)表示document中每个词的word embedding表示。文章则可以用所有词的embedding累加后的均值表示,即,最后从隐层再经过一次的非线性变换得到输出层的label。对比word2vec中的cbow模型(continuous bag of word),可以发现两个模型之前非常的相似。不同之处在于,fasttext模型最后预测的是文章的label,而cbow模型预测的是窗口中间的词w(t),一个是有监督的学习,一个是无监督的学习。另外cbow模型中输入层只包括当前窗口内除中心词的所以词,而fasttext模型中输出层是文章中的所有词。
和word2vec类似,fasttext本质上也可以看成是一个浅层的神经网络,因此其forward propogation过程可描述如下:
其中是最后输出层的输入向量,表示从隐层到输出层的权重。
由于模型的最后我们要预测文章属于某个类别的概率,因此很自然的选择就是softmax层了,于是损失函数可以定义为:
当类别数较少时,直接套用softmax层并没有效率问题,但是当类别很多时,softmax层的计算就比较费时了。为了加快训练过程,Fasttext同样也采用了和word2vec类似的方法。一种方法是使用hierarchical softmax,当类别数为K,word embedding大小为d时,计算复杂度可以从降到。另一种方法是采用negative sampling,即每次从除当前label外的其他label中选择几个作为负样本,作为出现负样本的概率加到损失函数中,用公式可表达为:
其中是第个样本的隐层,表示中第j行向量。
N-gram特征
到目前为止,Fasttext模型有个致命的问题,就是丢失了词顺序的信息,因为隐层是通过简单的求和取平均得到的。为了弥补这个不足,Fasttext增加了N-gram的特征。具体做法是把N-gram当成一个词,也用embedding向量来表示,在计算隐层时,把N-gram的embedding向量也加进去求和取平均。举个例子来说,假设某篇文章只有3个词,W1,W2,W3,N-gram的N取2,、、以及、分别表示词W1、W2、W3和bigram W1-W2,W2-W3的embedding向量,那么文章的隐层可表示为:
通过back-propogation算法,就可以同时学到词的Embeding和n-gram的Embedding了。
具体实现上,由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。如下图所示:
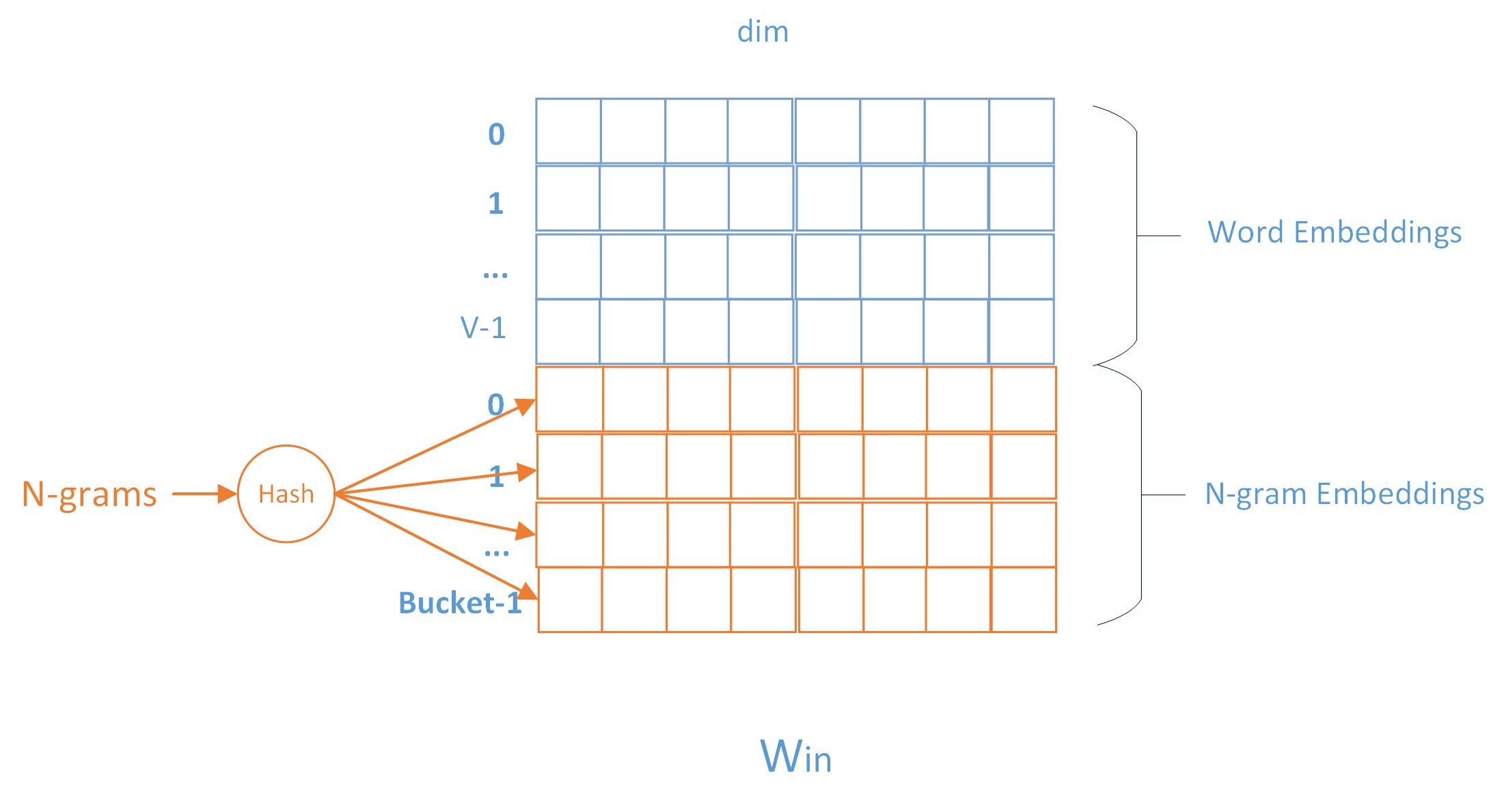
图中是Embedding矩阵,每行代表一个word或N-gram的embeddings向量,其中前行是word embeddings,后Buckets行是n-grams embeddings。每个n-gram经哈希函数哈希到0-bucket-1的位置,得到对应的embedding向量。用哈希的方式既能保证查找时的效率,又可能把内存消耗控制在范围内。不过这种方法潜在的问题是存在哈希冲突,不同的n-gram可能会共享同一个embedding。如果桶大小取的足够大,这种影响会很小。
Tricks
Fasttext为了提升计算效率做了很多方面的优化,除了上节提到的Hash方法外,还使用了很多小技巧,这对我们实际写代码的时候提供了很多的借鉴。
首先,对计算复杂度比较高的运算,Fasttext都采用了预计算的方法,先计算好值,使用的时候再查表,这是典型的空间或时间的优化思路。比如sigmoid函数的计算,源代码如下:
void initSigmoid() {
t_sigmoid = new real[SIGMOID_TABLE_SIZE + 1];
for (int i = 0; i < SIGMOID_TABLE_SIZE + 1; i++) {
real x = real(i * 2 * MAX_SIGMOID) / SIGMOID_TABLE_SIZE - MAX_SIGMOID;
t_sigmoid[i] = 1.0 / (1.0 + std::exp(-x));
}
}
其次,在Negative Sampling中,Fasttext也采用了和word2vec类似的方法,即按照每个词的词频进行随机负采样,词频越大的词,被采样的概率越大。每个词被采样的概率并不是简单的按照词频在总量的占比,而是对词频先取根号,再算占比,即。其中表示词的词频。这里取根号的目的是降低高频词的采用概率,同事增加低频词的采样概率,具体代码如下:
void Model::initTableNegatives(const std::vector<int64_t>& counts) {
real z = 0.0;
for (size_t i = 0; i < counts.size(); i++) {
z += pow(counts[i], 0.5);
}
for (size_t i = 0; i < counts.size(); i++) {
real c = pow(counts[i], 0.5);
for (size_t j = 0; j < c * NEGATIVE_TABLE_SIZE / z; j++) {
negatives.push_back(i);
}
}
std::shuffle(negatives.begin(), negatives.end(), rng);
}
使用说明
Fasttext的使用非常简单,首先从Github上clone源码到本地,然后直接make编译,生成一个可执行文件Fasttext。执行fasttext将打印使用帮助说明如下:
./fasttext
usage: fasttext <command> <args>
The commands supported by fasttext are:
supervised train a supervised classifier
test evaluate a supervised classifier
predict predict most likely label
predict_prob predict labels and probility
skipgram train a skipgram model
cbow train a cbow model
print-vectors print vectors given a trained model
帮助说明已经非常清楚了。如果要训练模型,我们选择supervised选项,执行./fasttext supervised:
./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-lr learning rate [0.05]
-lrUpdateRate change the rate of updates for the learning rate [100]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-minCount minimal number of word occurences [1]
-neg number of negatives sampled [5]
-wordNgrams max length of word ngram [1]
-loss loss function {ns, hs, softmax} [ns]
-bucket number of buckets [2000000]
-minn min length of char ngram [3]
-maxn max length of char ngram [6]
-thread number of threads [12]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
训练模式下涉及到的主要参数有学习率(-lr),隐层的维数(-dim),最小词频(-minCount),负采样个数(-neg)和n-grams的长度(-wordNgrams)等。
应用
弄清基本原理后,我们尝试了用Fasttext对微信的文章进行分类。首先先简单地说明下任务的背景:微信公众号的文章中有不少黑四类的文章(包括广告,活动,招聘和公告),比较影响用户体验,其中广告文章又占比较大的比例。因此我们希望从现有的文章数据中,训练出一个分类模型,自动识别每个文章是否属于广告。虽然是一个简单的二分类问题,但是考虑的广告文章本身的多样性,和正常文章界限较模糊,以及软文广告,图片广告等,要做到比较高的准确率还是有不少困难的。
先看下实验的数据集。我们通过人工标注,交叉验证的方式收集了约32.4万的样本,其中正样本(广告文章)15.7万,负样本(正常文章)16.7万。按照8:2的比例切分成训练数据和验证数据(用于调参)。另外还有1500左右的独立测试样本,正负样本占比为1:1。每个样本为一篇文章,包括文章的标题和正文。
实验中,我们选择了另外两种分类算法来和Fasttext进行对比。第一种方法是目前正在使用的广告特征词袋的方法,其中包括广告的特征词和bigram大约3万多个。同时对标题命中词袋和不同文章位置命中词袋进行了加权处理,另外还增加了标题和广告的相似度等特征。另一种方法是使用CNN+word2vec的方法,先用word2vec训练词的Embedding,然后把文章的词序列转化成Embeddings向量构成的二维矩阵,之后再套用CNN的网络架构进行分类,具体方法可参考这里。
Fasttext的参数选择上,我们使用-dim=64, -lr=0.5, -wordNgram=2 , -minCount=1,-bucket=10000000,-thread 20,其余参数默认。所有模型的一些超参数都通过验证集来选择最优的参数。
首先,我们从分类准确率的评价指标上对比三种方法的实际效果。
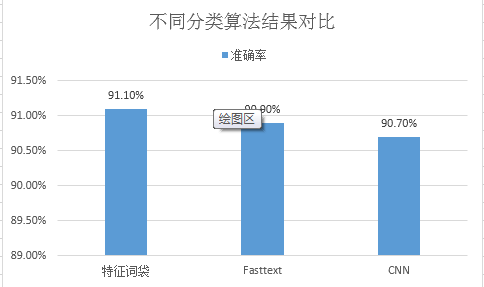
从实际效果上来看,Fasttext的表现还是非常不错的。虽然比特征词袋的方法要略差一点,但是特征词袋的结果是通过之前一系列的优化后的结果,而Fasttext只是通过了简单的调参,就能达到90.9%左右的准确率。同时,对比相对复杂一些的CNN的深度学习方法,分类效果还要略好一些。
从算法的执行效率上看,我们同样对这三种方法进行了简单地对比:

上图显示的是每种算法单次迭代的训练时间,单位是秒。可以看到Fasttext相对于深度学习等方法,在训练速度上的优势还是非常明显,单次迭代时长比CNN快了60多倍。而且Fasttext是在普通CPU上执行,而CNN是在k20的GPU下执行的结果。特征词袋的方法最后是用liblinear来训练,因为采用的是逻辑回归算法,比较简单,所以速度要比Fasttext快一些。
结论和思考
其实关于学术界对Fasttext的评价,网上也有许多不同的声音。有些人认为Fasttext模型非常简单,理论上也没有什么很多创新之处。但是从实际的使用效果和训练速度上来看,我认为Fasttext依然是一个非常优秀的开源文本分类工具。
首先从工业界的角度来看,Fasttext因为其优秀的性能,不错的分类效果,使用起来也非常简单,因此非常适合大规模的文本分类问题。实际上Facebook已经将Fasttext应用于实际的大规模文本分类的场景中了。另外作为浅层的文本分类模型,Fasttext也非常适合作为Baseline算法来和复杂的深度学习算法进行对比。
另一方面,从理论或者学术的角度看,Fasttext也引发了我们一些新的思考。首先,对于文本分类等偏线性的数据集,复杂的深层网络对于浅层网络来说,优势并不明显,深度学习可能容易过拟合,而浅层的简单网络反而泛化能力更好。但也不是说浅层的方法就一定比深层的好,这是由数据集来决定的。其次,除了数据本身,数据量的大小很大程度上也决定了方法的选择。对于小规模的数据集,可能简单的浅层模型就可以了,深度学习因为参数很多,模型复杂,反而训练不充分。但随着数据量的增加,可能深度模型的优势就逐步体现出来。不过深度学习受限于GPU本身的性能和内存问题,面对一些超大规模的数据集,深度学习可能无能无力。这时候,选择有些简单的浅层方法,反而是一个比较好的选择。